We are thrilled to announce the ESM Metagenomic Atlas (esmatlas.com)!
In this effort we folded the entirety of MGnify90 and are releasing all folded structures. This database contains >617 million structures, of which >225 million are predicted with high confidence.
Are you a computational biologist trying to embed some proteins? Jealous of NLP researchers for @huggingface's easy-to-use repository of models?
Come check out our re-release of our TAPE code (github.com/songlab-cal/ta…), complete with a huggingface-style API for loading models!
We have trained ESM3, a generative bidirectional masked language model that reasons over the sequence, structure, and function of proteins. ESM3 is trained at three model scales - 1.4B, 7B, and 98B.
x.com/alexrives/stat…
We have trained ESM3 and we're excited to introduce EvolutionaryScale.
ESM3 is a generative language model for programming biology. In experiments, we found ESM3 can simulate 500M years of evolution to generate new fluorescent proteins.
Read more: evolutionaryscale.ai/blog/esm3-rele…
Our new paper on unsupervised contact prediction with protein LMs is up on bioarxiv! Examining Transformers trained with MLM on protein sequences, we find attention maps predict contacts *better* than Potts models trained on the corresponding MSA. 1/12
Here’s a video of my talk! I tried to make it relatively accessible to people without much background in either biology or ML.
Definitely unbiased reviewers (my roommates) suggest I at least partially succeeded.
youtu.be/hcJS9d09ECA
TAPE v0.4 is released! In addition to a number of bugfixes, we've added the TRRosetta model for structure prediction so that you can play around with predicting structure in pytorch!
This is a helpful thread, but I want to point out that I and many others got into competitive PhD programs without having any publications.
Strong letters of recommendation can and will outweigh publications.
Are you applying for a PhD in Machine Learning, Artificial Intelligence, and beyond?
Here's a thread of high-quality resources that helped me understand the process + craft my application better. 👇
Working on ESM3 has been the most challenging and the most rewarding part of my career. I am incredibly proud of the team we have built - y’all make it so fun to come in to work each day.
I’m incredibly grateful to work with this amazing team. This is the most dedicated and creative team I’ve ever worked with, and I’m so excited to continue building. Please don’t hesitate to reach out if you’re interested!
Interesting paper! Arguably, this is exactly what our MSA Transformer is - a model that alternates between attention within a sequence and attention across different sequences.
Big difference is they use random mini batching as opposed to an explicit search fir related points.
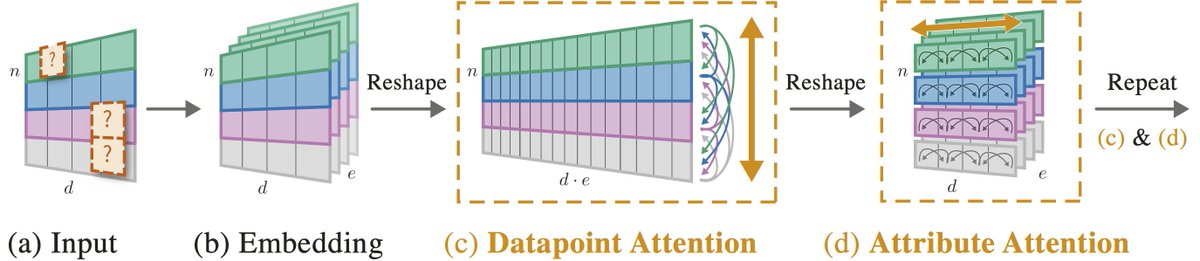
🗞New Paper🗞
🤖🧪Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning 🧪🤖
Huge thanks to @neilbband* as well as @clarelyle, @AidanNGomez, @tom_rainforth, @yaringal, and @OATML_Oxford !
Introducing 🚀Non-Parametric Transformers🚀 1/
I don't fully agree here. Large Deep Networks models can have emergent behavior, beyond what they are explicitly designed to do. I wouldn't have predicted that AlphaFold could model protein complexes, but it is clearly able to do so in some cases, even without paired MSAs. (1/5)
A reminder for bioinformaticians - AlphaFold works off the *real* multiple alignment, created by evolution. Flipping an amino acid in the target protein to model a mutation will not work in AlphaFold. Please don't do it. Please dont write papers about how it doesn't work.